O Scrapy é um framework todo prontinho pra lidar com a maioria dos problemas que enfrentamos ao fazer web scraping. Porém, é um tanto comum termos que extrair dados de páginas cuja parte do conteúdo seja gerada por código JavaScript, que é tipicamente executado no nosso navegador. Aí é que tá problema, pois o Scrapy não executa os scripts presentes no HTML. Tudo o que ele faz é baixar o HTML exatamente da forma que o servidor entrega.
Este post vai fazer um apanhado geral sobre algumas formas de lidar com páginas baseadas em JavaScript. Vamos começar vendo como saber se determinada informação que queremos extrair é gerada por código JavaScript ou não.
Como identificar uma página baseada em JavaScript
Um jeito simples de descobrir se as informações que queremos extrair são gerada por código JS é usando o nosso navegador. Carregue a página e então utilize a opção “Visualizar código-fonte”. Se o conteúdo que você quer extrair estiver ali representado em HTML, você pode ficar tranquilo, pois você poderá extraí-lo tranquilamente usando somente o Scrapy.
Nota: não utilize a opção “Inspecionar Elemento” (ferramentas do desenvolvedor) neste caso. Embora ela seja uma mão na roda pra descobrirmos como os dados estão estruturados, o problema é que ela já mostra o fonte da página após ter sido renderizada pelo browser (incluindo conteúdo gerado dinamicamente por código JS).
Por exemplo, abra http://quotes.toscrape.com. Esta página mostra frases de autores famosos e, se você abrir o código-fonte da página, verá que cada frase está representada por um bloco div.quote.
Entretanto, se você carregar a variação gerada por JavaScript → http://quotes.toscrape.com/js, você irá perceber que as frases não estão lá bonitinhas dentro do HTML. Na realidade, elas estão entranhadas em um trecho de código JavaScript presente na página, que é executado pelo motor JavaScript do navegador.
Outra opção é usar uma extensão pro navegador que permita desabilitar o JavaScript em uma aba, como o Quick JavaScript Switcher, e então verificar se os dados que queremos extrair estão na página mesmo após desabilitamos o JavaScript.
Bom, uma vez que identificamos que o conteúdo da página é gerado por código JavaScript, o próximo passo é usar alguma das soluções a seguir para que possamos lidar com páginas baseadas em JS usando o Scrapy.
1. Usando um navegador headless
Usando o Scrapy, podemos terceirizar a tarefa de renderizar a página completa para um navegador web. Assim, ao invés de utilizarmos o HTML baixado pelo Scrapy, vamos fazer com que um navegador baixe a página e execute o código JS pra gente e entregue como resposta o HTML prontinho. Uma opção legal para isso é o PhantomJS, que é um navegador headless e que pode ser facilmente integrado com Python via Selenium.
import scrapy
from selenium import webdriver
class QuotesSeleniumSpider(scrapy.Spider):
name = 'quotes-selenium'
start_urls = ['http://quotes.toscrape.com/js']
def __init__(self, *args, **kwargs):
self.driver = webdriver.PhantomJS()
super(QuotesSeleniumSpider, self).__init__(*args, **kwargs)
def parse(self, response):
self.driver.get(response.url)
sel = scrapy.Selector(text=self.driver.page_source)
for quote in sel.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.css('small.author::text').extract_first(),
'tags': quote.css('a.tag::text').extract()
}
next_page_url = response.css("li.next > a::attr(href)").extract_first()
if next_page_url is not None:
yield scrapy.Request(response.urljoin(next_page_url))
Nota: O spider acima requer o módulo Python para o Selenium, que pode ser instalado via pip install selenium. Também é necessária a instalação do binário do PhantomJS em algum lugar do seu PATH.
O spider acima instancia o driver selenium pro PhantomJS e, no método parse(), faz com que o PhantomJS baixe e renderize a página http://quotes.toscrape.com/js. O HTML renderizado (self.driver.page_source) é então usado para construir um objeto Selector que nos permite extrair dados usando os tradicionais seletores do Scrapy.
Contudo, quando executarmos o código acima, cada página será baixada duas vezes: uma pelo downloader do Scrapy e outra pelo método parse(), na chamada à self.driver.get(). Para evitar esse comportamento, podemos criar um downloader middleware que utilize o selenium para baixar a página ao invés do downloader do Scrapy. Você pode ver o código do middleware clicando aqui e um spider que utiliza tal middleware aqui.
2. Extraindo dados de dentro do código JavaScript
O código fonte da página http://quotes.toscrape.com/js nos mostra que as frases que são renderizadas pelo navegador estão dentro de um arrayzão JavaScript chamado data:
var data = [
{
"author": {
"goodreads_link": "/author/show/9810.Albert_Einstein",
"name": "Albert Einstein",
"slug": "Albert-Einstein"
},
"tags": ["Change", "deep-thoughts", "thinking", "world"],
"text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d"
},
{
"author": {
"goodreads_link": "/author/show/1077326.J_K_Rowling",
"name": "J.K. Rowling",
"slug": "J-K-Rowling"
},
"tags": ["abilities","choices"],
"text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d"
},
...
Os dados que queremos extrair já estão prontinhos dentro da página, então podemos extraí-los sem usar um navegador headless. Como os seletores do Scrapy apenas lidam com HTML/XML, vamos usar a lib js2xml para converter o array JavaScript acima para XML e então extrair os dados usando seletores Scrapy.
import scrapy
import js2xml
class QuotesJs2XmlSpider(scrapy.Spider):
name = 'quotes-js2xml'
start_urls = ['http://quotes.toscrape.com/js/']
def parse(self, response):
script = response.xpath('//script[contains(., "var data =")]/text()').extract_first()
script_as_xml = js2xml.parse(script)
sel = scrapy.Selector(_root=script_as_xml)
for quote in sel.xpath('//var[@name="data"]/array/object'):
yield {
'text': quote.xpath('string(./property[@name="text"])').extract_first(),
'author': quote.xpath(
'string(./property[@name="author"]//property[@name="name"])'
).extract_first(),
'tags': quote.xpath('./property[@name="tags"]//string/text()').extract(),
}
next_page_url = response.css("li.next > a::attr(href)").extract_first()
if next_page_url is not None:
yield scrapy.Request(response.urljoin(next_page_url))
No método parse() do spider acima primeiramente obtemos o código JS contido no elemento (linha 10) e então utilizamos o js2xml para convertê-lo para JavaScript. Depois disso, bastou construir um seletor Scrapy sobre tal valor e extrair os dados usando XPath (ou CSS).
Além de ter menos dependências, esta solução tem um desempenho melhor pois não depende do carregamento de um navegador (mesmo que seja headless como o PhantomJS) durante a execução.
3. Imitando o comportamento do navegador
A web está cheia de sites com conteúdo dinâmico carregado de acordo com ações do usuário. Por exemplo, o usuário de um e-commerce rola a página até o final e novos produtos são carregados automaticamente (a.k.a. rolagem infinita – infinite scrolling). Ou então o usuário clica em um botão que faz com que mais informações sejam mostradas sem recarregar a página.
Nesses casos, o que tipicamente acontece é que o navegador faz requisições AJAX que retornam mais informações quando determinado evento do usuário é disparado (scroll, click, etc).
Extrair dados de páginas desse tipo pode ser bem mais fácil do que a gente imagina. Ao invés de usar Selenium + PhantomJS, basta inspecionar as requisições AJAX que o navegador faz e imitá-las no nosso spider.
Considere a seguinte página: http://quotes.toscrape.com/scroll. A cada vez que rolamos ela até o fim, uma nova requisição é feita para a obtenção de novas frases que são então renderizadas pelo navegador. Para verificar quais requisições são feitas e para quais recursos, podemos usar o painel “Rede” das “Ferramentas do desenvolvedor” do nosso navegador favorito, como mostro abaixo no Chrome:
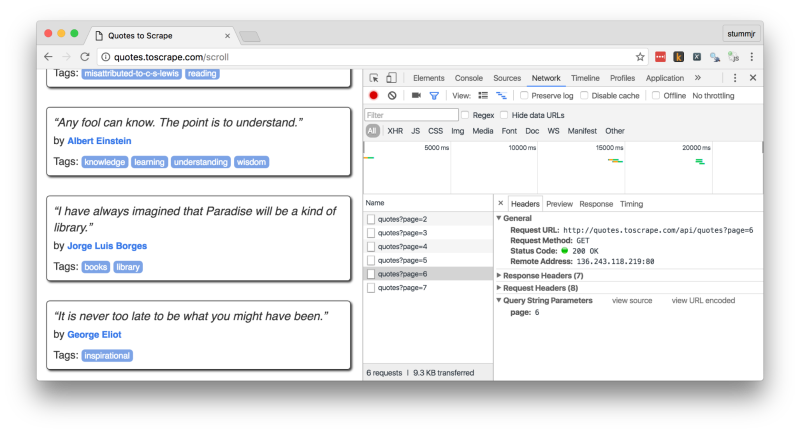
No nosso exemplo, os novos resultados são obtidos por requisições para http://quotes.toscrape.com/api/quotes?page= e a resposta para as requisições vem prontinha em formato JSON. Ou seja, nem precisaremos usar XPath ou CSS para extrair os dados:
import json
import scrapy
class QuotesAjaxSpider(scrapy.Spider):
name = 'quotes-ajax'
base_url = 'http://quotes.toscrape.com/api/quotes?page=%d'
start_urls = [base_url % 1]
def parse(self, response):
json_data = json.loads(response.text)
for quote in json_data['quotes']:
yield quote
if json_data['has_next']:
next_page = self.base_url % (int(json_data['page']) + 1)
yield scrapy.Request(url=next_page, callback=self.parse)
O spider acima imita as requisições AJAX feitas pelo navegador e obtém os dados de todas as frases do site.
Em geral, você pode fazer o mesmo para a maioria das páginas que usam AJAX. Algumas podem ser mais complicadinhas, requerendo que você envie alguns dados pré-computados (como hashes) como parâmetro, mas nada que uma boa investigada na página não resolva.
Por fim
Espero que este post tenha ajudado a desmistificar um pouco o scraping de páginas baseadas em JavaScript. Como você pôde ver, nem sempre precisamos recorrer a uma ferramenta externa para renderizar o JS para a gente. Basta entender melhor como o protocolo HTTP e o navegador funcionam para que possamos lidar com esse tipo de problema.
Em alguns casos mais complexos (e também mais raros), você precisará simular a interação do usuário com a página. Para isso, você pode usar os métodos do selenium webdriver ou então simular tal comportamento usando um script Lua com o Splash.
O código apresentado neste post está disponível em: https://github.com/stummjr/pythonhelp-scrapy-javascript/